What's the difference between UTF-8 and UTF-8 with BOM?
What’s different between UTF-8 and UTF-8 with BOM?
![]()
22 Answers 22
The UTF-8 BOM is a sequence of bytes at the start of a text stream ( 0xEF, 0xBB, 0xBF ) that allows the reader to more reliably guess a file as being encoded in UTF-8.
Normally, the BOM is used to signal the endianness of an encoding, but since endianness is irrelevant to UTF-8, the BOM is unnecessary.
According to the Unicode standard, the BOM for UTF-8 files is not recommended:
2.6 Encoding Schemes
. Use of a BOM is neither required nor recommended for UTF-8, but may be encountered in contexts where UTF-8 data is converted from other encoding forms that use a BOM or where the BOM is used as a UTF-8 signature. See the “Byte Order Mark” subsection in Section 16.8, Specials, for more information.
![]()
The other excellent answers already answered that:
- There is no official difference between UTF-8 and BOM-ed UTF-8
- A BOM-ed UTF-8 string will start with the three following bytes. EF BB BF
- Those bytes, if present, must be ignored when extracting the string from the file/stream.
But, as additional information to this, the BOM for UTF-8 could be a good way to «smell» if a string was encoded in UTF-8. Or it could be a legitimate string in any other encoding.
For example, the data [EF BB BF 41 42 43] could either be:
- The legitimate ISO-8859-1 string «ï»¿ABC»
- The legitimate UTF-8 string «ABC»
So while it can be cool to recognize the encoding of a file content by looking at the first bytes, you should not rely on this, as show by the example above
Encodings should be known, not divined.
![]()
There are at least three problems with putting a BOM in UTF-8 encoded files.
- Files that hold no text are no longer empty because they always contain the BOM.
- Files that hold text within the ASCII subset of UTF-8 are no longer themselves ASCII because the BOM is not ASCII, which makes some existing tools break down, and it can be impossible for users to replace such legacy tools.
- It is not possible to concatenate several files together because each file now has a BOM at the beginning.
And, as others have mentioned, it is neither sufficient nor necessary to have a BOM to detect that something is UTF-8:
- It is not sufficient because an arbitrary byte sequence can happen to start with the exact sequence that constitutes the BOM.
- It is not necessary because you can just read the bytes as if they were UTF-8; if that succeeds, it is, by definition, valid UTF-8.
![]()
Here are examples of the BOM usage that actually cause real problems and yet many people don’t know about it.
BOM breaks scripts
Shell scripts, Perl scripts, Python scripts, Ruby scripts, Node.js scripts or any other executable that needs to be run by an interpreter — all start with a shebang line which looks like one of those:
It tells the system which interpreter needs to be run when invoking such a script. If the script is encoded in UTF-8, one may be tempted to include a BOM at the beginning. But actually the "#!" characters are not just characters. They are in fact a magic number that happens to be composed out of two ASCII characters. If you put something (like a BOM) before those characters, then the file will look like it had a different magic number and that can lead to problems.
The shebang characters are represented by the same two bytes in extended ASCII encodings, including UTF-8, which is commonly used for scripts and other text files on current Unix-like systems. However, UTF-8 files may begin with the optional byte order mark (BOM); if the "exec" function specifically detects the bytes 0x23 and 0x21, then the presence of the BOM (0xEF 0xBB 0xBF) before the shebang will prevent the script interpreter from being executed. Some authorities recommend against using the byte order mark in POSIX (Unix-like) scripts,[14] for this reason and for wider interoperability and philosophical concerns. Additionally, a byte order mark is not necessary in UTF-8, as that encoding does not have endianness issues; it serves only to identify the encoding as UTF-8. [emphasis added]
BOM is illegal in JSON
Implementations MUST NOT add a byte order mark to the beginning of a JSON text.
BOM is redundant in JSON
Not only it is illegal in JSON, it is also not needed to determine the character encoding because there are more reliable ways to unambiguously determine both the character encoding and endianness used in any JSON stream (see this answer for details).
BOM breaks JSON parsers
Not only it is illegal in JSON and not needed, it actually breaks all software that determine the encoding using the method presented in RFC 4627:
Determining the encoding and endianness of JSON, examining the first four bytes for the NUL byte:
Now, if the file starts with BOM it will look like this:
- UTF-32BE doesn’t start with three NULs, so it won’t be recognized
- UTF-32LE the first byte is not followed by three NULs, so it won’t be recognized
- UTF-16BE has only one NUL in the first four bytes, so it won’t be recognized
- UTF-16LE has only one NUL in the first four bytes, so it won’t be recognized
Depending on the implementation, all of those may be interpreted incorrectly as UTF-8 and then misinterpreted or rejected as invalid UTF-8, or not recognized at all.
Additionally, if the implementation tests for valid JSON as I recommend, it will reject even the input that is indeed encoded as UTF-8, because it doesn’t start with an ASCII character < 128 as it should according to the RFC.
Other data formats
BOM in JSON is not needed, is illegal and breaks software that works correctly according to the RFC. It should be a nobrainer to just not use it then and yet, there are always people who insist on breaking JSON by using BOMs, comments, different quoting rules or different data types. Of course anyone is free to use things like BOMs or anything else if you need it — just don’t call it JSON then.
For other data formats than JSON, take a look at how it really looks like. If the only encodings are UTF-* and the first character must be an ASCII character lower than 128 then you already have all the information needed to determine both the encoding and the endianness of your data. Adding BOMs even as an optional feature would only make it more complicated and error prone.
Other uses of BOM
As for the uses outside of JSON or scripts, I think there are already very good answers here. I wanted to add more detailed info specifically about scripting and serialization, because it is an example of BOM characters causing real problems.
What’s different between UTF-8 and UTF-8 without BOM?
Short answer: In UTF-8, a BOM is encoded as the bytes EF BB BF at the beginning of the file.
Originally, it was expected that Unicode would be encoded in UTF-16/UCS-2. The BOM was designed for this encoding form. When you have 2-byte code units, it’s necessary to indicate which order those two bytes are in, and a common convention for doing this is to include the character U+FEFF as a «Byte Order Mark» at the beginning of the data. The character U+FFFE is permanently unassigned so that its presence can be used to detect the wrong byte order.
UTF-8 has the same byte order regardless of platform endianness, so a byte order mark isn’t needed. However, it may occur (as the byte sequence EF BB FF ) in data that was converted to UTF-8 from UTF-16, or as a «signature» to indicate that the data is UTF-8.
Without. As Martin Cote answered, the Unicode standard does not recommend it. It causes problems with non-BOM-aware software.
A better way to detect whether a file is UTF-8 is to perform a validity check. UTF-8 has strict rules about what byte sequences are valid, so the probability of a false positive is negligible. If a byte sequence looks like UTF-8, it probably is.
![]()
![]()
UTF-8 with BOM is better identified. I have reached this conclusion the hard way. I am working on a project where one of the results is a CSV file, including Unicode characters.
If the CSV file is saved without a BOM, Excel thinks it’s ANSI and shows gibberish. Once you add "EF BB BF" at the front (for example, by re-saving it using Notepad with UTF-8; or Notepad++ with UTF-8 with BOM), Excel opens it fine.
Prepending the BOM character to Unicode text files is recommended by RFC 3629: "UTF-8, a transformation format of ISO 10646", November 2003 at https://www.rfc-editor.org/rfc/rfc3629 (this last info found at: http://www.herongyang.com/Unicode/Notepad-Byte-Order-Mark-BOM-FEFF-EFBBBF.html)
Question: What’s different between UTF-8 and UTF-8 without a BOM? Which is better?
Here are some excerpts from the Wikipedia article on the byte order mark (BOM) that I believe offer a solid answer to this question.
On the meaning of the BOM and UTF-8:
The Unicode Standard permits the BOM in UTF-8, but does not require or recommend its use. Byte order has no meaning in UTF-8, so its only use in UTF-8 is to signal at the start that the text stream is encoded in UTF-8.
Argument for NOT using a BOM:
The primary motivation for not using a BOM is backwards-compatibility with software that is not Unicode-aware. Another motivation for not using a BOM is to encourage UTF-8 as the «default» encoding.
Argument FOR using a BOM:
The argument for using a BOM is that without it, heuristic analysis is required to determine what character encoding a file is using. Historically such analysis, to distinguish various 8-bit encodings, is complicated, error-prone, and sometimes slow. A number of libraries are available to ease the task, such as Mozilla Universal Charset Detector and International Components for Unicode.
Programmers mistakenly assume that detection of UTF-8 is equally difficult (it is not because of the vast majority of byte sequences are invalid UTF-8, while the encodings these libraries are trying to distinguish allow all possible byte sequences). Therefore not all Unicode-aware programs perform such an analysis and instead rely on the BOM.
In particular, Microsoft compilers and interpreters, and many pieces of software on Microsoft Windows such as Notepad will not correctly read UTF-8 text unless it has only ASCII characters or it starts with the BOM, and will add a BOM to the start when saving text as UTF-8. Google Docs will add a BOM when a Microsoft Word document is downloaded as a plain text file.
On which is better, WITH or WITHOUT the BOM:
The IETF recommends that if a protocol either (a) always uses UTF-8, or (b) has some other way to indicate what encoding is being used, then it “SHOULD forbid use of U+FEFF as a signature.”
My Conclusion:
Use the BOM only if compatibility with a software application is absolutely essential.
Also note that while the referenced Wikipedia article indicates that many Microsoft applications rely on the BOM to correctly detect UTF-8, this is not the case for all Microsoft applications. For example, as pointed out by @barlop, when using the Windows Command Prompt with UTF-8 † , commands such type and more do not expect the BOM to be present. If the BOM is present, it can be problematic as it is for other applications.
† The chcp command offers support for UTF-8 (without the BOM) via code page 65001.
Utf 8 без bom что это
Если не ошибаюсь, UTF-8 без BOM это кодировка, в которой каждому символу соответствует 1 байт. А просто UTF-8 тоже самое только в начале файла идут символы ef bb bf (в HEX)
Я всё правильно понял? Какой из них лучше использовать когда сохраняешь файлы?
И ещё. Что значит строчка в статус-баре Notepad++"ANSI AS UTF-8"? Это когда выбираешь кодировку "UTF-8 без BOM"
без BOM.
если сохраните с ним, то на файлах, где есть сессии или заголовки, будет ошибка.
Если написать в utf-8 файл в 3 символа, русский пробел и английский
‘З Z’
покажет без BOM
d0 97 20 5a
а с ним
ef bb bf d0 97 20 5a
т.е. два байта там только первая буква, bom это три байта
причём если набрать в строке "Выполнить" charmap
, выбрать юникод-шрифт, например "Arial"
, то символ З там записан как U+0417 Cirrilic Capital Letter Ze
а Z как U+005a Latin Capital Letter Z
т.е. чтобы файл не весил в два раза больше, из юникода сделали utf-8,
но я что-то не понял зачем сделали d097 из 0417, просто лень лезть искать чего почитать, из-за какой-то мелочи ,)
BOM актуален только для UTF-16 и UTF-32. В UTF-8 вообще нет такого понятия как BOM.
В notepad++ есть UTF-8 с BOM и без.
То что судя по всему в UTF-8 есть такое понятие как BOM. Вот попробовал сохранить русский текст с помощью notepad++ в кодировке UTF-8 без BOM — размер файла в байтах равен количеству символов (1 байт — 1 символ). Потом тот же текст просто в UTF-8 — получился файл на 3 байта больше, т.е. в начало файла добавился этот BOM, разве нет?
Понятием BOM является символ Byte Order Mark из набора UNICODE (а значит он есть в любых Unicode Transformation Formats — не важно 8-ми , 16-и или 32-разрядных.)
Другое дело, что всё же — применительно к www — кодировку UTF-8 стараются использовать по умолчанию, без этого символа (поскольку он мешает php-обработке). На этом, видимо, Саня и хотел сделать акцент.
Сам по себе этот символ никакой значимой информации (помимо того, что по его байтовому представлению можно опознать конкретную форму UNICODE) не несет.
Нужно смотреть не на то, что написано в редакторе, а на то, что написано в стандарте.
BOM = Byte Order Mark = метка порядка следования байтов. Стандарт не определяет порядок следования байтов в UTF-8.
Поэтому три символа в начале файла с кодами EF BB BF нельзя считать BOM. На самом деле эта сигнатура обозначает, что дальше идёт текст в формате UTF-8.
> размер файла в байтах равен количеству символов (1 байт — 1 символ)
Это верно только для символов с кодом менее 128.
В UTF-8 порядок следования байтов определен, (равно как и порядок следования бит в кодовых позициях байтов) и определен весьма жестко.
В начале файла нет трех символов с кодами EF BB BF
В начале файла есть три байта EF BB BF, представляющие один символ — Byte Order Mark (0. 0FEFFu).
>Это верно только для символов с кодом менее 128.
Ну пожалуй соглашусь, только что замутил файл который состоял из 94 символов и весил 188 байт без БОМ и 191 с БОМ.
Utf 8 без bom что это
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров, т.е. нечитаемых символов.
Что такое кодировка?
Упрощенно говоря, кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
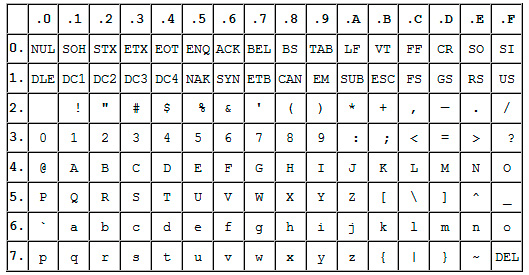
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII, предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
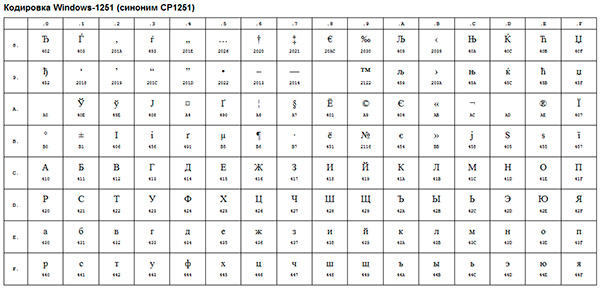
ANSI-кодировка — это собирательное название. В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу.
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16.
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это многобайтовая кодировка с переменной длинной символа. Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, phpDesigner, rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
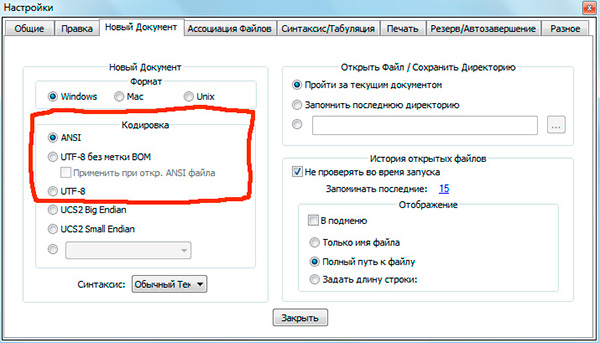
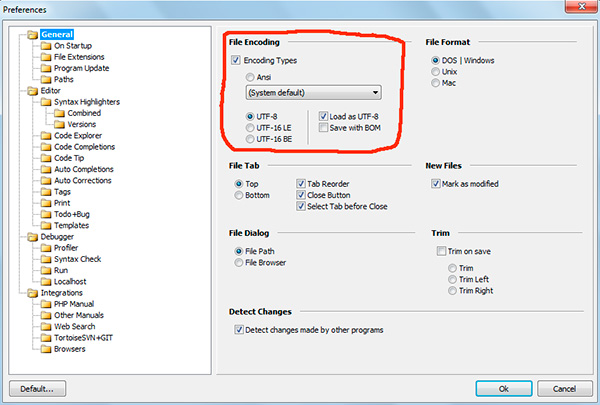
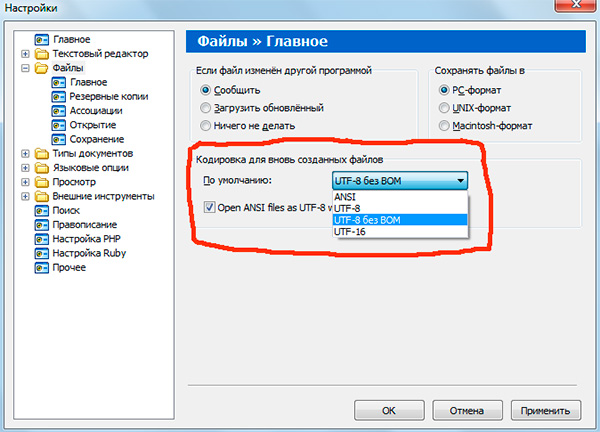
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM.
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark. Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.

Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.

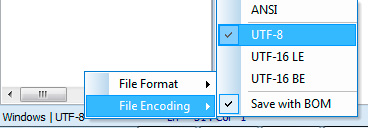
В программе phpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).

В редакторе rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции head вашего html-документа:
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
Дмитрий Науменко.
P.S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
UTF-8 и UTF-8 (без BOM)
Вчера заказал новый дорогой хостинг для своих проектов. Впервые столкнулся с такой жуткой проблемой кодировки, целый день убил. Благо, грамотные и отзывчивые люди с суппорта подсказали, что у меня кодировка файлов в UTF-8, а нужно было сохранять в UTF-8 (без BOM) :smoke:
А вот и вопрос, чем же эти 2 кодировки отличаются? 🙂
UTF-8 без BOM это кодировка, в которой каждому символу соответствует 1 байт (специально для тех, кто выхватывает куски — речь только о ЛАТИНИЦЕ).
— просто UTF8 (UTF16 UTF32) (Byte Order Mark (метка порядка следования байтов)) тоже самое только в начале файла идут символы ef bb bf (в HEX)
mff, во первых — одна кодировка, а не две 🙂
во вторых — совсем небольшое отличие структуры файла, если файл сохранен в режиме utf-8(с BOM), то он выглядит как 3 байта, индентифицирующие utf кодировку файла, которые и называются «BOM запись» (bom = byte order mask), для utf-8, utf-16, utf-32 разные бом записи, поэтому это может создать проблему при их «распознавании», а если вы знаете в какой у вас кодировке файл, то эти 3 байта можно опустить и записать просто один «текст» — режим utf-8(без bom)
вот кстати эти 3 байта для ютф8: EF BB BF
bearman добавил 17.05.2010 в 15:42
реально?) если да, то я лох раз думал что это просто «метка»
ну блин. ну неужели и тебе нуна разжевывать? когда-то писал для пионеров, которые никак не могли понять, чем отличается длина строки в символах и в байтах (с бомом и без (естественно для латиници))
Спасибо ребят, всё предельно ясно теперь! T.R.O.N, отдельное спасибо! Не раз выручайте с моими глупыми вопросами. ��
T.R.O.N, то есть при бом, латиница будет кодироваться двумя байтами?))
ну хватит детского сада. или для Вас открытие, что для многих осилить вычитание лишних 3-х байтов, это как полет на Луну?
сохранил в notepad++ в режиме utf8+ bom
и открыл в редакторе от winrar’а
не вижу двух байт 🙂
а вот если сохранить такой же текст в utf-16, то да, будет 2 байта на символ латиницы (даже) если я не путаю с utf-32, при работе с пхп редко с такими кодировками приходится общаться, поэтому по памяти говорю 🙂
bearman добавил 17.05.2010 в 16:10
utf-8 и utf-8+bom ничем не отличаются, кроме этих 3 байт, ты с этим согласен? или я стар, глуп и туп стал и не понимаю что эти вещи различаются не только 3 байтами?
utf-8 — байтопеременная кодировка, от 1 до 4 байт в зависимости от кодируемого символа, бом на это свойство никак не влияет